<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<!-- Put site-specific property overrides in this file. -->
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<!-- Put site-specific property overrides in this file. -->
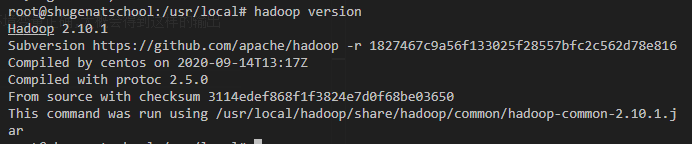
20/12/13 11:31:39 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = shugenatschool/10.101.3.195 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.10.1 STARTUP_MSG: classpath = /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/netty-3.10.6.Final.jar:/usr/local/hadoop/share/hadoop/common/lib/jersey-core-1.9.jar:/usr/local/hadoop/share/hadoop/common/lib/asm-3.2.jar:/usr/local/hadoop/share/hadoop/common/lib/servlet-api-2.5.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-cli-1.2.jar:/usr/local/hadoop/share/hadoop/common/lib/gson-2.2.4.jar:/usr/local/hadoop/share/hadoop/common/lib/zookeeper-3.4.14.jar:/usr/local/hadoop/share/hadoop/common/lib/guava-11.0.2.jar:/usr/local/hadoop/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/share/hadoop/common/lib/json-smart-1.3.1.jar:/usr/local/hadoop/share/hadoop/common/lib/curator-recipes-2.13.0.jar:/usr/local/hadoop/share/hadoop/common/lib/spotbugs-annotations-3.1.9.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-collections-3.2.2.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-math3-3.1.1.jar:/usr/local/hadoop/share/hadoop/common/lib/nimbus-jose-jwt-7.9.jar:/usr/local/hadoop/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/usr/local/hadoop/share/hadoop/common/lib/jets3t-0.9.0.jar:/usr/local/hadoop/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/usr/local/hadoop/share/hadoop/common/lib/snappy-java-1.0.5.jar:/usr/local/hadoop/share/hadoop/common/lib/jetty-util-6.1.26.jar:/usr/local/hadoop/share/hadoop/common/lib/paranamer-2.3.jar:/usr/local/hadoop/share/hadoop/common/lib/audience-annotations-0.5.0.jar:/usr/local/hadoop/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/usr/local/hadoop/share/hadoop/common/lib/jetty-sslengine-6.1.26.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-net-3.1.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-lang3-3.4.jar:/usr/local/hadoop/share/hadoop/common/lib/xmlenc-0.52.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-beanutils-1.9.4.jar:/usr/local/hadoop/share/hadoop/common/lib/hadoop-auth-2.10.1.jar:/usr/local/hadoop/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/usr/local/hadoop/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/usr/local/hadoop/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/usr/local/hadoop/share/hadoop/common/lib/httpcore-4.4.4.jar:/usr/local/hadoop/share/hadoop/common/lib/stax-api-1.0-2.jar:/usr/local/hadoop/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/usr/local/hadoop/share/hadoop/common/lib/hadoop-annotations-2.10.1.jar:/usr/local/hadoop/share/hadoop/common/lib/jettison-1.1.jar:/usr/local/hadoop/share/hadoop/common/lib/curator-framework-2.13.0.jar:/usr/local/hadoop/share/hadoop/common/lib/curator-client-2.13.0.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-io-2.4.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-configuration-1.6.jar:/usr/local/hadoop/share/hadoop/common/lib/junit-4.11.jar:/usr/local/hadoop/share/hadoop/common/lib/jsp-api-2.1.jar:/usr/local/hadoop/share/hadoop/common/lib/stax2-api-3.1.4.jar:/usr/local/hadoop/share/hadoop/common/lib/jcip-annotations-1.0-1.jar:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-digester-1.8.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-codec-1.4.jar:/usr/local/hadoop/share/hadoop/common/lib/jsch-0.1.55.jar:/usr/local/hadoop/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/usr/local/hadoop/share/hadoop/common/lib/slf4j-api-1.7.25.jar:/usr/local/hadoop/share/hadoop/common/lib/mockito-all-1.8.5.jar:/usr/local/hadoop/share/hadoop/common/lib/jersey-json-1.9.jar:/usr/local/hadoop/share/hadoop/common/lib/log4j-1.2.17.jar:/usr/local/hadoop/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/share/hadoop/common/lib/httpclient-4.5.2.jar:/usr/local/hadoop/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/usr/local/hadoop/share/hadoop/common/lib/jersey-server-1.9.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-lang-2.6.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-logging-1.1.3.jar:/usr/local/hadoop/share/hadoop/common/lib/commons-compress-1.19.jar:/usr/local/hadoop/share/hadoop/common/lib/hamcrest-core-1.3.jar:/usr/local/hadoop/share/hadoop/common/lib/jsr305-3.0.2.jar:/usr/local/hadoop/share/hadoop/common/lib/activation-1.1.jar:/usr/local/hadoop/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar:/usr/local/hadoop/share/hadoop/common/lib/jetty-6.1.26.jar:/usr/local/hadoop/share/hadoop/common/lib/woodstox-core-5.0.3.jar:/usr/local/hadoop/share/hadoop/common/lib/avro-1.7.7.jar:/usr/local/hadoop/share/hadoop/common/hadoop-common-2.10.1-tests.jar:/usr/local/hadoop/share/hadoop/common/hadoop-nfs-2.10.1.jar:/usr/local/hadoop/share/hadoop/common/hadoop-common-2.10.1.jar:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/netty-3.10.6.Final.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/asm-3.2.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/guava-11.0.2.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jackson-core-2.9.10.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/okhttp-2.7.5.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/netty-all-4.1.50.Final.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/commons-io-2.4.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jackson-annotations-2.9.10.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/hadoop-hdfs-client-2.10.1.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/xercesImpl-2.12.0.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jackson-databind-2.9.10.6.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/okio-1.6.0.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/xml-apis-1.4.01.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jsr305-3.0.2.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/htrace-core4-4.1.0-incubating.jar:/usr/local/hadoop/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-rbf-2.10.1-tests.jar:/usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-nfs-2.10.1.jar:/usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-native-client-2.10.1.jar:/usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-2.10.1.jar:/usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-native-client-2.10.1-tests.jar:/usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-client-2.10.1-tests.jar:/usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-client-2.10.1.jar:/usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-2.10.1-tests.jar:/usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-rbf-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/netty-3.10.6.Final.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jersey-client-1.9.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jersey-core-1.9.jar:/usr/local/hadoop/share/hadoop/yarn/lib/asm-3.2.jar:/usr/local/hadoop/share/hadoop/yarn/lib/servlet-api-2.5.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-cli-1.2.jar:/usr/local/hadoop/share/hadoop/yarn/lib/gson-2.2.4.jar:/usr/local/hadoop/share/hadoop/yarn/lib/ehcache-3.3.1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/zookeeper-3.4.14.jar:/usr/local/hadoop/share/hadoop/yarn/lib/aopalliance-1.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/guava-11.0.2.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/share/hadoop/yarn/lib/HikariCP-java7-2.4.12.jar:/usr/local/hadoop/share/hadoop/yarn/lib/json-smart-1.3.1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/curator-recipes-2.13.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/spotbugs-annotations-3.1.9.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-math3-3.1.1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/nimbus-jose-jwt-7.9.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jets3t-0.9.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/api-asn1-api-1.0.0-M20.jar:/usr/local/hadoop/share/hadoop/yarn/lib/snappy-java-1.0.5.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/usr/local/hadoop/share/hadoop/yarn/lib/paranamer-2.3.jar:/usr/local/hadoop/share/hadoop/yarn/lib/audience-annotations-0.5.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jetty-sslengine-6.1.26.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-net-3.1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/guice-3.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-lang3-3.4.jar:/usr/local/hadoop/share/hadoop/yarn/lib/xmlenc-0.52.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-beanutils-1.9.4.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/usr/local/hadoop/share/hadoop/yarn/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/usr/local/hadoop/share/hadoop/yarn/lib/fst-2.50.jar:/usr/local/hadoop/share/hadoop/yarn/lib/apacheds-i18n-2.0.0-M15.jar:/usr/local/hadoop/share/hadoop/yarn/lib/httpcore-4.4.4.jar:/usr/local/hadoop/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/usr/local/hadoop/share/hadoop/yarn/lib/json-io-2.5.1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/api-util-1.0.0-M20.jar:/usr/local/hadoop/share/hadoop/yarn/lib/metrics-core-3.0.1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jettison-1.1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/usr/local/hadoop/share/hadoop/yarn/lib/curator-framework-2.13.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/curator-client-2.13.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-io-2.4.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-configuration-1.6.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jsp-api-2.1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/java-util-1.9.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/stax2-api-3.1.4.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jcip-annotations-1.0-1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-digester-1.8.jar:/usr/local/hadoop/share/hadoop/yarn/lib/mssql-jdbc-6.2.1.jre7.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-codec-1.4.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jsch-0.1.55.jar:/usr/local/hadoop/share/hadoop/yarn/lib/java-xmlbuilder-0.4.jar:/usr/local/hadoop/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jersey-json-1.9.jar:/usr/local/hadoop/share/hadoop/yarn/lib/geronimo-jcache_1.0_spec-1.0-alpha-1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/log4j-1.2.17.jar:/usr/local/hadoop/share/hadoop/yarn/lib/javax.inject-1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/share/hadoop/yarn/lib/httpclient-4.5.2.jar:/usr/local/hadoop/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jersey-server-1.9.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-lang-2.6.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/usr/local/hadoop/share/hadoop/yarn/lib/commons-compress-1.19.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jsr305-3.0.2.jar:/usr/local/hadoop/share/hadoop/yarn/lib/activation-1.1.jar:/usr/local/hadoop/share/hadoop/yarn/lib/htrace-core4-4.1.0-incubating.jar:/usr/local/hadoop/share/hadoop/yarn/lib/jetty-6.1.26.jar:/usr/local/hadoop/share/hadoop/yarn/lib/woodstox-core-5.0.3.jar:/usr/local/hadoop/share/hadoop/yarn/lib/avro-1.7.7.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-common-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-server-timeline-pluginstorage-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-registry-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-server-tests-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-server-router-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-api-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-server-common-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.10.1.jar:/usr/local/hadoop/share/hadoop/yarn/hadoop-yarn-client-2.10.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/netty-3.10.6.Final.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/asm-3.2.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/snappy-java-1.0.5.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/guice-3.0.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/hadoop-annotations-2.10.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/junit-4.11.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/javax.inject-1.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/commons-compress-1.19.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/usr/local/hadoop/share/hadoop/mapreduce/lib/avro-1.7.7.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.10.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.10.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.10.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.10.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.10.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.10.1-tests.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.10.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.10.1.jar:/usr/local/hadoop/contrib/capacity-scheduler/*.jar STARTUP_MSG: build = https://github.com/apache/hadoop -r 1827467c9a56f133025f28557bfc2c562d78e816; compiled by 'centos' on 2020-09-14T13:17Z STARTUP_MSG: java = 1.8.0_275 ************************************************************/ 20/12/13 11:31:39 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 20/12/13 11:31:40 INFO namenode.NameNode: createNameNode [-format] Formatting using clusterid: CID-17273503-35c6-49ff-a837-e628584a6685 20/12/13 11:31:41 INFO namenode.FSEditLog: Edit logging is async:true 20/12/13 11:31:41 INFO namenode.FSNamesystem: KeyProvider: null 20/12/13 11:31:41 INFO namenode.FSNamesystem: fsLock is fair: true 20/12/13 11:31:41 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false 20/12/13 11:31:41 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE) 20/12/13 11:31:41 INFO namenode.FSNamesystem: supergroup = supergroup 20/12/13 11:31:41 INFO namenode.FSNamesystem: isPermissionEnabled = true 20/12/13 11:31:41 INFO namenode.FSNamesystem: HA Enabled: false 20/12/13 11:31:41 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling 20/12/13 11:31:41 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000 20/12/13 11:31:41 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 20/12/13 11:31:41 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 20/12/13 11:31:41 INFO blockmanagement.BlockManager: The block deletion will start around 2020 Dec 13 11:31:41 20/12/13 11:31:41 INFO util.GSet: Computing capacity for map BlocksMap 20/12/13 11:31:41 INFO util.GSet: VM type = 64-bit 20/12/13 11:31:41 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB 20/12/13 11:31:41 INFO util.GSet: capacity = 2^21 = 2097152 entries 20/12/13 11:31:41 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 20/12/13 11:31:41 WARN conf.Configuration: No unit for dfs.heartbeat.interval(3) assuming SECONDS 20/12/13 11:31:41 WARN conf.Configuration: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS 20/12/13 11:31:41 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 20/12/13 11:31:41 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0 20/12/13 11:31:41 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000 20/12/13 11:31:41 INFO blockmanagement.BlockManager: defaultReplication = 3 20/12/13 11:31:41 INFO blockmanagement.BlockManager: maxReplication = 512 20/12/13 11:31:41 INFO blockmanagement.BlockManager: minReplication = 1 20/12/13 11:31:41 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 20/12/13 11:31:41 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 20/12/13 11:31:41 INFO blockmanagement.BlockManager: encryptDataTransfer = false 20/12/13 11:31:41 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 20/12/13 11:31:41 INFO namenode.FSNamesystem: Append Enabled: true 20/12/13 11:31:41 INFO namenode.FSDirectory: GLOBAL serial map: bits=24 maxEntries=16777215 20/12/13 11:31:41 INFO util.GSet: Computing capacity for map INodeMap 20/12/13 11:31:41 INFO util.GSet: VM type = 64-bit 20/12/13 11:31:41 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB 20/12/13 11:31:41 INFO util.GSet: capacity = 2^20 = 1048576 entries 20/12/13 11:31:41 INFO namenode.FSDirectory: ACLs enabled? false 20/12/13 11:31:41 INFO namenode.FSDirectory: XAttrs enabled? true 20/12/13 11:31:41 INFO namenode.NameNode: Caching file names occurring more than 10 times 20/12/13 11:31:41 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: falseskipCaptureAccessTimeOnlyChange: false 20/12/13 11:31:41 INFO util.GSet: Computing capacity for map cachedBlocks 20/12/13 11:31:41 INFO util.GSet: VM type = 64-bit 20/12/13 11:31:41 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB 20/12/13 11:31:41 INFO util.GSet: capacity = 2^18 = 262144 entries 20/12/13 11:31:41 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 20/12/13 11:31:41 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 20/12/13 11:31:41 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 20/12/13 11:31:42 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 20/12/13 11:31:42 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 20/12/13 11:31:42 INFO util.GSet: Computing capacity for map NameNodeRetryCache 20/12/13 11:31:42 INFO util.GSet: VM type = 64-bit 20/12/13 11:31:42 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB 20/12/13 11:31:42 INFO util.GSet: capacity = 2^15 = 32768 entries 20/12/13 11:31:42 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1937264665-10.101.3.195-1607830302045 20/12/13 11:31:42 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted. 20/12/13 11:31:42 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 20/12/13 11:31:42 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds . 20/12/13 11:31:42 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 20/12/13 11:31:42 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown. 20/12/13 11:31:42 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at shugenatschool/10.101.3.195 ************************************************************/
我们之需要看到这一句就行了。
1
20/12/13 11:31:42 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted.
启动 hadoop
执行命令start-dfs.sh
应该会得到下列输出:
1 2 3 4 5
Starting namenodes on [shugenatschool] shugenatschool: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-shugenatschool.out localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-shugenatschool.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-shugenatschool.out
接着执行命令start-yarn.sh
应该会得到下列输出:
1 2 3
starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-shugenatschool.out localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-shugenatschool.out
这时候 hadoop 应该算是启动完成了。
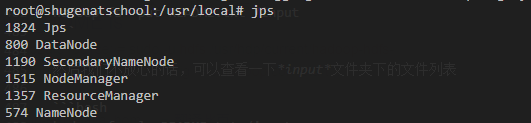
我们可以用jps看看正在运行的 hadoop 进程
应该会得到下列类似输出:
运行 wordcount 样例程序
添加输入文件
首先在 HDFS 中创建输入文件夹(没有输出)
1
hadoop fs -mkdir /input
然后把要统计的文件丢进去,我们这里以README.txt为例子,(没有输出)
1
hadoop fs -put README.txt /input
然后我们不放心的话,可以查看一下input文件夹下的文件列表
1
hadoop fs -ls README.txt /input
应该会得到下列类似输出
执行样例程序
1
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar wordcount /input /output
20/12/13 12:06:32 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 20/12/13 12:06:32 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 20/12/13 12:06:32 INFO input.FileInputFormat: Total input files to process : 1 20/12/13 12:06:32 INFO mapreduce.JobSubmitter: number of splits:1 20/12/13 12:06:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local327845771_0001 20/12/13 12:06:33 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 20/12/13 12:06:33 INFO mapreduce.Job: Running job: job_local327845771_0001 20/12/13 12:06:33 INFO mapred.LocalJobRunner: OutputCommitter set in config null 20/12/13 12:06:33 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 20/12/13 12:06:33 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup \_temporary folders under output directory:false, ignore cleanup failures: false 20/12/13 12:06:33 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 20/12/13 12:06:33 INFO mapred.LocalJobRunner: Waiting for map tasks 20/12/13 12:06:33 INFO mapred.LocalJobRunner: Starting task: attempt_local327845771_0001_m_000000_0 20/12/13 12:06:34 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 20/12/13 12:06:34 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup \_temporary folders under output directory:false, ignore cleanup failures: false 20/12/13 12:06:34 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 20/12/13 12:06:34 INFO mapred.MapTask: Processing split: hdfs://shugenatschool:9000/input/README.txt:0+1366 20/12/13 12:06:34 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 20/12/13 12:06:34 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 20/12/13 12:06:34 INFO mapred.MapTask: soft limit at 83886080 20/12/13 12:06:34 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 20/12/13 12:06:34 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 20/12/13 12:06:34 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 20/12/13 12:06:34 INFO mapred.LocalJobRunner: 20/12/13 12:06:34 INFO mapred.MapTask: Starting flush of map output 20/12/13 12:06:34 INFO mapred.MapTask: Spilling map output 20/12/13 12:06:34 INFO mapred.MapTask: bufstart = 0; bufend = 2055; bufvoid = 104857600 20/12/13 12:06:34 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26213684(104854736); length = 713/6553600 20/12/13 12:06:34 INFO mapred.MapTask: Finished spill 0 20/12/13 12:06:34 INFO mapred.Task: Task:attempt_local327845771_0001_m_000000_0 is done. And is in the process of committing 20/12/13 12:06:34 INFO mapred.LocalJobRunner: map 20/12/13 12:06:34 INFO mapred.Task: Task 'attempt_local327845771_0001_m_000000_0' done. 20/12/13 12:06:34 INFO mapred.Task: Final Counters for attempt_local327845771_0001_m_000000_0: Counters: 23 File System Counters FILE: Number of bytes read=303493 FILE: Number of bytes written=798348 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=1366 HDFS: Number of bytes written=0 HDFS: Number of read operations=5 HDFS: Number of large read operations=0 HDFS: Number of write operations=1 Map-Reduce Framework Map input records=31 Map output records=179 Map output bytes=2055 Map output materialized bytes=1836 Input split bytes=108 Combine input records=179 Combine output records=131 Spilled Records=131 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=13 Total committed heap usage (bytes)=243269632 File Input Format Counters Bytes Read=1366 20/12/13 12:06:34 INFO mapred.LocalJobRunner: Finishing task: attempt_local327845771_0001_m_000000_0 20/12/13 12:06:34 INFO mapred.LocalJobRunner: map task executor complete. 20/12/13 12:06:34 INFO mapred.LocalJobRunner: Waiting for reduce tasks 20/12/13 12:06:34 INFO mapred.LocalJobRunner: Starting task: attempt_local327845771_0001_r_000000_0 20/12/13 12:06:34 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 20/12/13 12:06:34 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 20/12/13 12:06:34 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 20/12/13 12:06:34 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@781b9f43 20/12/13 12:06:34 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshold=10 20/12/13 12:06:34 INFO reduce.EventFetcher: attempt_local327845771_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 20/12/13 12:06:34 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local327845771_0001_m_000000_0 decomp: 1832 len: 1836 to MEMORY 20/12/13 12:06:34 INFO reduce.InMemoryMapOutput: Read 1832 bytes from map-output for attempt_local327845771_0001_m_000000_0 20/12/13 12:06:34 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 1832, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->1832 20/12/13 12:06:34 WARN io.ReadaheadPool: Failed readahead on ifile EBADF: Bad file descriptor at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method) at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267) at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146) at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:208) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) 20/12/13 12:06:34 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 20/12/13 12:06:34 INFO mapreduce.Job: Job job_local327845771_0001 running in uber mode : false 20/12/13 12:06:34 INFO mapreduce.Job: map 100% reduce 0% 20/12/13 12:06:34 INFO mapred.LocalJobRunner: 1 / 1 copied. 20/12/13 12:06:34 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 20/12/13 12:06:34 INFO mapred.Merger: Merging 1 sorted segments 20/12/13 12:06:34 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 1823 bytes 20/12/13 12:06:34 INFO reduce.MergeManagerImpl: Merged 1 segments, 1832 bytes to disk to satisfy reduce memory limit 20/12/13 12:06:34 INFO reduce.MergeManagerImpl: Merging 1 files, 1836 bytes from disk 20/12/13 12:06:34 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce 20/12/13 12:06:34 INFO mapred.Merger: Merging 1 sorted segments 20/12/13 12:06:34 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 1823 bytes 20/12/13 12:06:34 INFO mapred.LocalJobRunner: 1 / 1 copied. 20/12/13 12:06:34 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 20/12/13 12:06:35 INFO mapred.Task: Task:attempt_local327845771_0001_r_000000_0 is done. And is in the process of committing 20/12/13 12:06:35 INFO mapred.LocalJobRunner: 1 / 1 copied. 20/12/13 12:06:35 INFO mapred.Task: Task attempt_local327845771_0001_r_000000_0 is allowed to commit now 20/12/13 12:06:35 INFO output.FileOutputCommitter: Saved output of task 'attempt_local327845771_0001_r_000000_0' to hdfs://shugenatschool:9000/output/\_temporary/0/task_local327845771_0001_r_000000 20/12/13 12:06:35 INFO mapred.LocalJobRunner: reduce > reduce 20/12/13 12:06:35 INFO mapred.Task: Task 'attempt_local327845771_0001_r_000000_0' done. 20/12/13 12:06:35 INFO mapred.Task: Final Counters for attempt_local327845771_0001_r_000000_0: Counters: 29 File System Counters FILE: Number of bytes read=307197 FILE: Number of bytes written=800184 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=1366 HDFS: Number of bytes written=1306 HDFS: Number of read operations=8 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Map-Reduce Framework Combine input records=0 Combine output records=0 Reduce input groups=131 Reduce shuffle bytes=1836 Reduce input records=131 Reduce output records=131 Spilled Records=131 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=0 Total committed heap usage (bytes)=243269632 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Output Format Counters Bytes Written=1306 20/12/13 12:06:35 INFO mapred.LocalJobRunner: Finishing task: attempt_local327845771_0001_r_000000_0 20/12/13 12:06:35 INFO mapred.LocalJobRunner: reduce task executor complete. 20/12/13 12:06:35 INFO mapreduce.Job: map 100% reduce 100% 20/12/13 12:06:35 INFO mapreduce.Job: Job job_local327845771_0001 completed successfully 20/12/13 12:06:35 INFO mapreduce.Job: Counters: 35 File System Counters FILE: Number of bytes read=610690 FILE: Number of bytes written=1598532 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=2732 HDFS: Number of bytes written=1306 HDFS: Number of read operations=13 HDFS: Number of large read operations=0 HDFS: Number of write operations=4 Map-Reduce Framework Map input records=31 Map output records=179 Map output bytes=2055 Map output materialized bytes=1836 Input split bytes=108 Combine input records=179 Combine output records=131 Reduce input groups=131 Reduce shuffle bytes=1836 Reduce input records=131 Reduce output records=131 Spilled Records=262 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=13 Total committed heap usage (bytes)=486539264 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1366 File Output Format Counters Bytes Written=1306